10 Jahre iSynth

Synthetische Daten sind süsse Daten

Wie aus einem Brainstroming an einem Freitagnachmittag ein Prototyp entstand, und aus dem Prototypen eine Lösung, die bis auf den heutigen Tag prosperiert. Ein persönlicher Rückblick auf die Entstehung von iSynth.
Letzte Woche haben wir bei itopia eine imaginäre Zeitmarke passiert: Vor 10 Jahren wurde der Grundstein für iSynth gelegt, unserer Lösung zum Generieren von synthetischen Daten.
Am 31. Juli 2015, einem heissen Freitagnachmittag, haben Josef Bösze und ich diskutiert, wie man synthetische Daten richtig machen sollte. Wir steckten damals in einem grossen Kernbanken-Migrationsprojekt und hatten bereits viel Erfahrung gesammelt mit der Bereitstellung von synthetischen Daten fürs Offshore Testing. Unsere damalige Lösung - eine Erweiterung unseres Migrationsframeworks - hatte ihre Grenzen. Und die spürten wir langsam.
Die Grundideen, die Josef und ich damals diskutiert haben, bilden nach wie vor das Fundament von iSynth:
- Daten sollten ständig neu produziert und wieder verbraucht werden können
- Die Rezepte zum Generieren von Daten sollten in textueller Form vorliegen, damit sie unter Versionskontrolle gehalten werden können
- keine eigene DSL, wir entschieden uns für Python als ideale Sprache zur Manipulation von Daten und Datenstrukturen
- Daten müssen aus einer Top-Down-Optik als Objekte modelliert werden, nicht Bottom-up aus Sicht von relationalen Tabellen
- Wir wollten Datenkonstellationen visualisieren, um diese einfach zu reflektieren
Mit diesen Ideen im Kopf habe ich bereits auf dem Heimweg begonnen, einen minimalen Prototypen zu bauen. Und bereits am Montagvormittag konnte ich Josef die allererste Konstellation vorlegen:
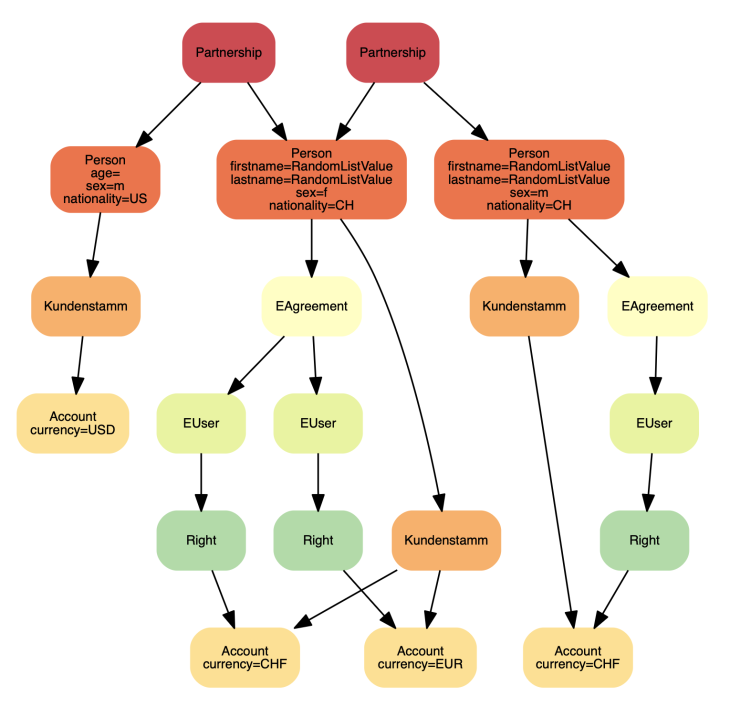
Dank dem Vertrauen und des unternehmerischen Muts unseres damaligen Geschäftsführers René Stierli hatten wir grünes Licht, diesen Prototypen zu einer funktionierenden Lösung weiterzuentwickeln. Und so waren wir 2016 erstmals in der Lage, mit iSynth im grossen Stil synthetische Daten zu generieren. Die Zielplattform war eine Schulungsumgebung, die fünf aufeinander integrierte Appliationen umfasste (Stammdatenverwaltung, CRM, Kontoführung, Zahlungssystem sowie Outputmanagement). Sie wurde mit ca. 200'000 Kundenkonstellationen gefüllt.
Wir haben iSynth seither stetig weiterentwickelt und zusammen mit unseren Kunden in verschiedensten Gebieten zur Anwendung bringen dürfen. Und so geht die Reise weiter!
Mein Fazit, wenn ich auf diese 10 Jahre zurückblicke:
- Es braucht ganz viel Enthusiasmus und Durchhaltewillen, einen solchen Weg zu beschreiten.
- Das Verständnis über das eigene Business und die eigenen Datenstrukturen ist eine Grundvoraussetzung, um sinnvolle Testdaten zu produzieren - egal auf welchem Weg.
- Sinnvolle Testdaten stellen für viele Projekte bzw. Unternehmen immer noch eine Herausforderung dar.
- Die Akzeptanz für synthetische Daten steigt langsam, aber stetig.
- Die Datenschutz-Thematik ist zwar wichtig, aber vor allem ein erfreulicher Nebeneffekt. Beim Einsatz von synthetischen Daten geht es vor allem darum, in den Entwicklungs- und QS-Prozessen besser und schneller zu werden - Stichwort Continuous Delivery.
- Zu Containerplattformen, CI/CD Pipelines und automatisierten Tests habe ich jede Menge gelernt.
- Python ist und bleibt eine ausgezeichnete Programmiersprache. ;-)
Ich freue mich schon auf die nächsten 10 Jahre!